導讀跟大家講解下有關如何用爬蟲下載中國土地市場網的土地成交數據?,相信小伙伴們對這個話題應該也很關注吧,現在就為小伙伴們說說如何用爬蟲
跟大家講解下有關如何用爬蟲下載中國土地市場網的土地成交數據?,相信小伙伴們對這個話題應該也很關注吧,現在就為小伙伴們說說如何用爬蟲下載中國土地市場網的土地成交數據?,小編也收集到了有關如何用爬蟲下載中國土地市場網的土地成交數據?的相關資料,希望大家看到了會喜歡。
作為畢業狗想研究下土地出讓方面的信息,需要每一筆的土地出讓數據。想從中國土地市場網的土地成交結果公告(http://www.landchina.com/default.aspx?tabid=263&ComName=default)中點擊每一筆土地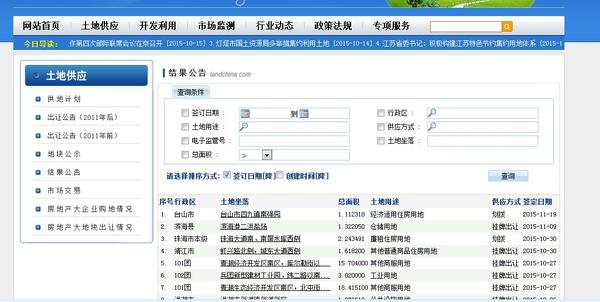 ,在跳轉后的詳細頁面中下載“土地用途” “成交價格” “供地方式” “項目位置”等信息,
,在跳轉后的詳細頁面中下載“土地用途” “成交價格” “供地方式” “項目位置”等信息,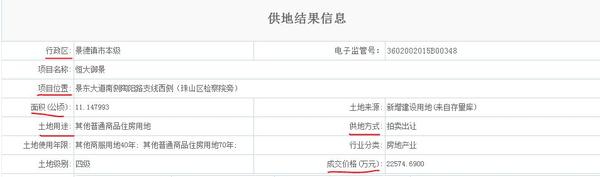 由于共有100多萬筆土地成交信息,手動查找是不可能了,想問下能不能用爬蟲給下載下來?以及預計難度和耗費時間?跪謝各位。回復內容:#!/usr/bin/env python# -*- coding: utf-8 -*-import requestsfrom bs4 import BeautifulSoupimport timeimport randomimport sysdef get_post_data(url, headers): # 訪問一次網頁,獲取post需要的信息 data = { 'TAB_QuerySubmitSortData': '', 'TAB_RowButtonActionControl': '', } try: req = requests.get(url, headers=headers) except Exception, e: print 'get baseurl failed, try again!', e sys.exit(1) try: soup = BeautifulSoup(req.text,"html.parser") TAB_QueryConditionItem = soup.find( 'input', id="TAB_QueryConditionItem270").get('value') # print TAB_QueryConditionItem data['TAB_QueryConditionItem'] = TAB_QueryConditionItem TAB_QuerySortItemList = soup.find( 'input', id="TAB_QuerySort0").get('value') # print TAB_QuerySortItemList data['TAB_QuerySortItemList'] = TAB_QuerySortItemList data['TAB_QuerySubmitOrderData'] = TAB_QuerySortItemList __EVENTVALIDATION = soup.find( 'input', id='__EVENTVALIDATION').get('value') # print __EVENTVALIDATION data['__EVENTVALIDATION'] = __EVENTVALIDATION __VIEWSTATE = soup.find('input', id='__VIEWSTATE').get('value') # print __VIEWSTATE data['__VIEWSTATE'] = __VIEWSTATE except Exception, e: print 'get post data failed, try again!', e sys.exit(1) return datadef get_info(url, headers): req = requests.get(url, headers=headers) soup = BeautifulSoup(req.text,"html.parser") items = soup.find( 'table', id="mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1") # 所需信息組成字典 info = {} # 行政區 division = items.find( 'span', id="mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r1_c2_ctrl").get_text().encode('utf-8') info['XingZhengQu'] = division # 項目位置 location = items.find( 'span', id="mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r16_c2_ctrl").get_text().encode('utf-8') info['XiangMuWeiZhi'] = location # 面積(公頃) square = items.find( 'span', id="mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r2_c2_ctrl").get_text().encode('utf-8') info['MianJi'] = square # 土地用途 purpose = items.find( 'span', id="mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r3_c2_ctrl").get_text().encode('utf-8') info['TuDiYongTu'] = purpose # 供地方式 source = items.find( 'span', id="mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r3_c4_ctrl").get_text().encode('utf-8') info['GongDiFangShi'] = source # 成交價格(萬元) price = items.find( 'span', id="mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r20_c4_ctrl").get_text().encode('utf-8') info['ChengJiaoJiaGe'] = price # print info # 用唯一值的電子監管號當key, 所需信息當value的字典 all_info = {} Key_ID = items.find( 'span', id="mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r1_c4_ctrl").get_text().encode('utf-8') all_info[Key_ID] = info return all_infodef get_pages(baseurl, headers, post_data, date): print 'date', date # 補全post data post_data['TAB_QuerySubmitConditionData'] = post_data[ 'TAB_QueryConditionItem'] + ':' + date page = 1 while True: print ' page {0}'.format(page) # 休息一下,防止被網頁識別為爬蟲機器人 time.sleep(random.random() * 3) post_data['TAB_QuerySubmitPagerData'] = str(page) req = requests.post(baseurl, data=post_data, headers=headers) # print req soup = BeautifulSoup(req.text,"html.parser") items = soup.find('table', id="TAB_contentTable").find_all( 'tr', onmouseover=True) # print items for item in items: print item.find('td').get_text() link = item.find('a') if link: print item.find('a').text url = 'http://www.landchina.com/' + item.find('a').get('href') print get_info(url, headers) else: print 'no content, this ten days over' return break page += 1if __name__ =="__main__": # time.time() baseurl = 'http://www.landchina.com/default.aspx?tabid=263' headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.71 Safari/537.36', 'Host': 'www.landchina.com' } post_data = (get_post_data(baseurl, headers)) date = '2015-11-21~2015-11-30' get_pages(baseurl, headers, post_data, date)不請自來,知乎首答,同為大四畢業狗之前幫老師爬過這個信息,從1995年-2015年有170多萬條,算了下時間需要40多個小時才能爬完。我爬到2000年就沒有繼續爬了。當時寫代碼的時候剛學爬蟲,不懂原理,發現這個網頁點擊下一頁以及改變日期后,網址是不會變的,網址是不會變的,網址是不會變的Orz,對于新手來說根本不知道是為什么。后來就去找辦法,學了點selenium,利用它來模擬瀏覽器操作,更改日期、點擊下一頁什么的都可以實現了。好處是簡單粗暴,壞處是殺雞用牛刀,占用了系統太多資源。再到后來,學會了一點抓包技術,知道了原來日期和換頁都是通過post請求的。今天下午就把程序修改了一下,用post代替了原來的selenium。廢話不說,上代碼了。# -*- coding: gb18030 -*-'landchina 爬起來!'import requestsimport csvfrom bs4 import BeautifulSoupimport datetimeimport reimport osclass Spider(): def __init__(self): self.url='http://www.landchina.com/default.aspx?tabid=263' #這是用post要提交的數據 self.postData={ 'TAB_QueryConditionItem':'9f2c3acd-0256-4da2-a659-6949c4671a2a', 'TAB_QuerySortItemList':'282:False', #日期 'TAB_QuerySubmitConditionData':'9f2c3acd-0256-4da2-a659-6949c4671a2a:', 'TAB_QuerySubmitOrderData':'282:False', #第幾頁 'TAB_QuerySubmitPagerData':''} self.rowName=[u'行政區',u'電子監管號',u'項目名稱',u'項目位置',u'面積(公頃)',u'土地來源',u'土地用途',u'供地方式',u'土地使用年限',u'行業分類',u'土地級別',u'成交價格(萬元)',u'土地使用權人',u'約定容積率下限',u'約定容積率上限',u'約定交地時間',u'約定開工時間',u'約定竣工時間',u'實際開工時間',u'實際竣工時間',u'批準單位',u'合同簽訂日期'] #這是要抓取的數據,我把除了分期約定那四項以外的都抓取了 self.info=[ 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r1_c2_ctrl',#0 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r1_c4_ctrl',#1 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r17_c2_ctrl',#2 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r16_c2_ctrl',#3 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r2_c2_ctrl',#4 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r2_c4_ctrl',#5 #這條信息是土地來源,抓取下來的是數字,它要經過換算得到土地來源,不重要,我就沒弄了 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r3_c2_ctrl',#6 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r3_c4_ctrl',#7 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r19_c2_ctrl', #8 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r19_c4_ctrl',#9 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r20_c2_ctrl',#10 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r20_c4_ctrl',#11## 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f3_r2_c1_0_ctrl',## 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f3_r2_c2_0_ctrl',## 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f3_r2_c3_0_ctrl',## 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f3_r2_c4_0_ctrl', 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r9_c2_ctrl',#12 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f2_r1_c2_ctrl', 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f2_r1_c4_ctrl', 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r21_c4_ctrl', 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r22_c2', 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r22_c4_ctrl', 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r10_c2_ctrl', 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r10_c4_ctrl', 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r14_c2_ctrl', 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r14_c4_ctrl']#第一步 def handleDate(self,year,month,day): #返回日期數據 'return date format %Y-%m-%d' date=datetime.date(year,month,day)# print date.datetime.datetime.strftime('%Y-%m-%d') return date #日期對象 def timeDelta(self,year,month): #計算一個月有多少天 date=datetime.date(year,month,1) try: date2=datetime.date(date.year,date.month+1,date.day) except: date2=datetime.date(date.year+1,1,date.day) dateDelta=(date2-date).days return dateDelta def getPageContent(self,pageNum,date): #指定日期和頁數,打開對應網頁,獲取內容 postData=self.postData.copy() #設置搜索日期 queryDate=date.strftime('%Y-%m-%d')+'~'+date.strftime('%Y-%m-%d') postData['TAB_QuerySubmitConditionData']+=queryDate #設置頁數 postData['TAB_QuerySubmitPagerData']=str(pageNum) #請求網頁 r=requests.post(self.url,data=postData,timeout=30) r.encoding='gb18030' pageContent=r.text# f=open('content.html','w')# f.write(content.encode('gb18030'))# f.close() return pageContent#第二步 def getAllNum(self,date): #1無內容 2只有1頁 3 1—200頁 4 200頁以上 firstContent=self.getPageContent(1,date) if u'沒有檢索到相關數據' in firstContent: print date,'have','0 page' return 0 pattern=re.compile(u'共(.*?)頁.*?') result=re.search(pattern,firstContent) if result==None: print date,'have','1 page' return 1 if int(result.group(1))<=200: print date,'have',int(result.group(1)),'page' return int(result.group(1)) else: print date,'have','200 page' return 200#第三步 def getLinks(self,pageNum,date): 'get all links' pageContent=self.getPageContent(pageNum,date) links=[] pattern=re.compile(u'',re.S) results=re.findall(pattern,pageContent) for result in results: links.append('http://www.landchina.com/default.aspx?tabid=386'+result) return links def getAllLinks(self,allNum,date): pageNum=1 allLinks=[] while pageNum<=allNum: links=self.getLinks(pageNum,date) allLinks+=links print 'scrapy link from page',pageNum,'/',allNum pageNum+=1 print date,'have',len(allLinks),'link' return allLinks #第四步 def getLinkContent(self,link): 'open the link to get the linkContent' r=requests.get(link,timeout=30) r.encoding='gb18030' linkContent=r.text# f=open('linkContent.html','w')# f.write(linkContent.encode('gb18030'))# f.close() return linkContent def getInfo(self,linkContent):"get every item's info"data=[] soup=BeautifulSoup(linkContent) for item in self.info: if soup.find(id=item)==None: s='' else: s=soup.find(id=item).string if s==None: s='' data.append(unicode(s.strip())) return data def saveInfo(self,data,date): fileName= 'landchina/'+datetime.datetime.strftime(date,'%Y')+'/'+datetime.datetime.strftime(date,'%m')+'/'+datetime.datetime.strftime(date,'%d')+'.csv' if os.path.exists(fileName): mode='ab' else: mode='wb' csvfile=file(fileName,mode) writer=csv.writer(csvfile) if mode=='wb': writer.writerow([name.encode('gb18030') for name in self.rowName]) writer.writerow([d.encode('gb18030') for d in data]) csvfile.close() def mkdir(self,date): #創建目錄 path = 'landchina/'+datetime.datetime.strftime(date,'%Y')+'/'+datetime.datetime.strftime(date,'%m') isExists=os.path.exists(path) if not isExists: os.makedirs(path) def saveAllInfo(self,allLinks,date): for (i,link) in enumerate(allLinks): linkContent=data=None linkContent=self.getLinkContent(link) data=self.getInfo(linkContent) self.mkdir(date) self.saveInfo(data,date) print 'save info from link',i+1,'/',len(allLinks) 你可以去神箭手云爬蟲開發平臺看看。在云上簡單幾行js就可以實現爬蟲,如果這都懶得做也可以聯系官方進行定制,任何網站都可以爬,總之是個很方便的爬蟲基礎設施平臺。這個結構化如此清晰的數據,要采集這個數據是很容易的。 通過多年的數據處理經驗,可以給你以下幾個建議:1. 多線程2. 防止封IP3. 用Mongdb存儲大型非結構化數據了解更多可以訪問探碼科技大數據介紹頁面:http://www.tanmer.com/bigdata我抓過這個網站的結束合同,還是比較好抓的。抓完生成表格,注意的就是選擇欄的異步地區等內容,需要對他的js下載下來隊形異步請求。提交數據即可。請求的時候在他的主頁有一個id。好像是這么個東西,去年做的,記不清了,我有源碼可以給你分享。用java寫的我是爬蟲小白,請教下,不是說不能爬取asp的頁面嗎?詳細內容頁的地址是”default.aspx?tabid=386&comname=default&wmguid=75c725。。。“,網站是在default.aspx頁讀取數據庫顯示詳細信息,不是說讀不到數據庫里的數據嗎?
由于共有100多萬筆土地成交信息,手動查找是不可能了,想問下能不能用爬蟲給下載下來?以及預計難度和耗費時間?跪謝各位。回復內容:#!/usr/bin/env python# -*- coding: utf-8 -*-import requestsfrom bs4 import BeautifulSoupimport timeimport randomimport sysdef get_post_data(url, headers): # 訪問一次網頁,獲取post需要的信息 data = { 'TAB_QuerySubmitSortData': '', 'TAB_RowButtonActionControl': '', } try: req = requests.get(url, headers=headers) except Exception, e: print 'get baseurl failed, try again!', e sys.exit(1) try: soup = BeautifulSoup(req.text,"html.parser") TAB_QueryConditionItem = soup.find( 'input', id="TAB_QueryConditionItem270").get('value') # print TAB_QueryConditionItem data['TAB_QueryConditionItem'] = TAB_QueryConditionItem TAB_QuerySortItemList = soup.find( 'input', id="TAB_QuerySort0").get('value') # print TAB_QuerySortItemList data['TAB_QuerySortItemList'] = TAB_QuerySortItemList data['TAB_QuerySubmitOrderData'] = TAB_QuerySortItemList __EVENTVALIDATION = soup.find( 'input', id='__EVENTVALIDATION').get('value') # print __EVENTVALIDATION data['__EVENTVALIDATION'] = __EVENTVALIDATION __VIEWSTATE = soup.find('input', id='__VIEWSTATE').get('value') # print __VIEWSTATE data['__VIEWSTATE'] = __VIEWSTATE except Exception, e: print 'get post data failed, try again!', e sys.exit(1) return datadef get_info(url, headers): req = requests.get(url, headers=headers) soup = BeautifulSoup(req.text,"html.parser") items = soup.find( 'table', id="mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1") # 所需信息組成字典 info = {} # 行政區 division = items.find( 'span', id="mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r1_c2_ctrl").get_text().encode('utf-8') info['XingZhengQu'] = division # 項目位置 location = items.find( 'span', id="mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r16_c2_ctrl").get_text().encode('utf-8') info['XiangMuWeiZhi'] = location # 面積(公頃) square = items.find( 'span', id="mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r2_c2_ctrl").get_text().encode('utf-8') info['MianJi'] = square # 土地用途 purpose = items.find( 'span', id="mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r3_c2_ctrl").get_text().encode('utf-8') info['TuDiYongTu'] = purpose # 供地方式 source = items.find( 'span', id="mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r3_c4_ctrl").get_text().encode('utf-8') info['GongDiFangShi'] = source # 成交價格(萬元) price = items.find( 'span', id="mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r20_c4_ctrl").get_text().encode('utf-8') info['ChengJiaoJiaGe'] = price # print info # 用唯一值的電子監管號當key, 所需信息當value的字典 all_info = {} Key_ID = items.find( 'span', id="mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r1_c4_ctrl").get_text().encode('utf-8') all_info[Key_ID] = info return all_infodef get_pages(baseurl, headers, post_data, date): print 'date', date # 補全post data post_data['TAB_QuerySubmitConditionData'] = post_data[ 'TAB_QueryConditionItem'] + ':' + date page = 1 while True: print ' page {0}'.format(page) # 休息一下,防止被網頁識別為爬蟲機器人 time.sleep(random.random() * 3) post_data['TAB_QuerySubmitPagerData'] = str(page) req = requests.post(baseurl, data=post_data, headers=headers) # print req soup = BeautifulSoup(req.text,"html.parser") items = soup.find('table', id="TAB_contentTable").find_all( 'tr', onmouseover=True) # print items for item in items: print item.find('td').get_text() link = item.find('a') if link: print item.find('a').text url = 'http://www.landchina.com/' + item.find('a').get('href') print get_info(url, headers) else: print 'no content, this ten days over' return break page += 1if __name__ =="__main__": # time.time() baseurl = 'http://www.landchina.com/default.aspx?tabid=263' headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.71 Safari/537.36', 'Host': 'www.landchina.com' } post_data = (get_post_data(baseurl, headers)) date = '2015-11-21~2015-11-30' get_pages(baseurl, headers, post_data, date)不請自來,知乎首答,同為大四畢業狗之前幫老師爬過這個信息,從1995年-2015年有170多萬條,算了下時間需要40多個小時才能爬完。我爬到2000年就沒有繼續爬了。當時寫代碼的時候剛學爬蟲,不懂原理,發現這個網頁點擊下一頁以及改變日期后,網址是不會變的,網址是不會變的,網址是不會變的Orz,對于新手來說根本不知道是為什么。后來就去找辦法,學了點selenium,利用它來模擬瀏覽器操作,更改日期、點擊下一頁什么的都可以實現了。好處是簡單粗暴,壞處是殺雞用牛刀,占用了系統太多資源。再到后來,學會了一點抓包技術,知道了原來日期和換頁都是通過post請求的。今天下午就把程序修改了一下,用post代替了原來的selenium。廢話不說,上代碼了。# -*- coding: gb18030 -*-'landchina 爬起來!'import requestsimport csvfrom bs4 import BeautifulSoupimport datetimeimport reimport osclass Spider(): def __init__(self): self.url='http://www.landchina.com/default.aspx?tabid=263' #這是用post要提交的數據 self.postData={ 'TAB_QueryConditionItem':'9f2c3acd-0256-4da2-a659-6949c4671a2a', 'TAB_QuerySortItemList':'282:False', #日期 'TAB_QuerySubmitConditionData':'9f2c3acd-0256-4da2-a659-6949c4671a2a:', 'TAB_QuerySubmitOrderData':'282:False', #第幾頁 'TAB_QuerySubmitPagerData':''} self.rowName=[u'行政區',u'電子監管號',u'項目名稱',u'項目位置',u'面積(公頃)',u'土地來源',u'土地用途',u'供地方式',u'土地使用年限',u'行業分類',u'土地級別',u'成交價格(萬元)',u'土地使用權人',u'約定容積率下限',u'約定容積率上限',u'約定交地時間',u'約定開工時間',u'約定竣工時間',u'實際開工時間',u'實際竣工時間',u'批準單位',u'合同簽訂日期'] #這是要抓取的數據,我把除了分期約定那四項以外的都抓取了 self.info=[ 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r1_c2_ctrl',#0 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r1_c4_ctrl',#1 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r17_c2_ctrl',#2 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r16_c2_ctrl',#3 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r2_c2_ctrl',#4 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r2_c4_ctrl',#5 #這條信息是土地來源,抓取下來的是數字,它要經過換算得到土地來源,不重要,我就沒弄了 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r3_c2_ctrl',#6 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r3_c4_ctrl',#7 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r19_c2_ctrl', #8 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r19_c4_ctrl',#9 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r20_c2_ctrl',#10 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r20_c4_ctrl',#11## 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f3_r2_c1_0_ctrl',## 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f3_r2_c2_0_ctrl',## 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f3_r2_c3_0_ctrl',## 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f3_r2_c4_0_ctrl', 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r9_c2_ctrl',#12 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f2_r1_c2_ctrl', 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f2_r1_c4_ctrl', 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r21_c4_ctrl', 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r22_c2', 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r22_c4_ctrl', 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r10_c2_ctrl', 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r10_c4_ctrl', 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r14_c2_ctrl', 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r14_c4_ctrl']#第一步 def handleDate(self,year,month,day): #返回日期數據 'return date format %Y-%m-%d' date=datetime.date(year,month,day)# print date.datetime.datetime.strftime('%Y-%m-%d') return date #日期對象 def timeDelta(self,year,month): #計算一個月有多少天 date=datetime.date(year,month,1) try: date2=datetime.date(date.year,date.month+1,date.day) except: date2=datetime.date(date.year+1,1,date.day) dateDelta=(date2-date).days return dateDelta def getPageContent(self,pageNum,date): #指定日期和頁數,打開對應網頁,獲取內容 postData=self.postData.copy() #設置搜索日期 queryDate=date.strftime('%Y-%m-%d')+'~'+date.strftime('%Y-%m-%d') postData['TAB_QuerySubmitConditionData']+=queryDate #設置頁數 postData['TAB_QuerySubmitPagerData']=str(pageNum) #請求網頁 r=requests.post(self.url,data=postData,timeout=30) r.encoding='gb18030' pageContent=r.text# f=open('content.html','w')# f.write(content.encode('gb18030'))# f.close() return pageContent#第二步 def getAllNum(self,date): #1無內容 2只有1頁 3 1—200頁 4 200頁以上 firstContent=self.getPageContent(1,date) if u'沒有檢索到相關數據' in firstContent: print date,'have','0 page' return 0 pattern=re.compile(u'共(.*?)頁.*?') result=re.search(pattern,firstContent) if result==None: print date,'have','1 page' return 1 if int(result.group(1))<=200: print date,'have',int(result.group(1)),'page' return int(result.group(1)) else: print date,'have','200 page' return 200#第三步 def getLinks(self,pageNum,date): 'get all links' pageContent=self.getPageContent(pageNum,date) links=[] pattern=re.compile(u'',re.S) results=re.findall(pattern,pageContent) for result in results: links.append('http://www.landchina.com/default.aspx?tabid=386'+result) return links def getAllLinks(self,allNum,date): pageNum=1 allLinks=[] while pageNum<=allNum: links=self.getLinks(pageNum,date) allLinks+=links print 'scrapy link from page',pageNum,'/',allNum pageNum+=1 print date,'have',len(allLinks),'link' return allLinks #第四步 def getLinkContent(self,link): 'open the link to get the linkContent' r=requests.get(link,timeout=30) r.encoding='gb18030' linkContent=r.text# f=open('linkContent.html','w')# f.write(linkContent.encode('gb18030'))# f.close() return linkContent def getInfo(self,linkContent):"get every item's info"data=[] soup=BeautifulSoup(linkContent) for item in self.info: if soup.find(id=item)==None: s='' else: s=soup.find(id=item).string if s==None: s='' data.append(unicode(s.strip())) return data def saveInfo(self,data,date): fileName= 'landchina/'+datetime.datetime.strftime(date,'%Y')+'/'+datetime.datetime.strftime(date,'%m')+'/'+datetime.datetime.strftime(date,'%d')+'.csv' if os.path.exists(fileName): mode='ab' else: mode='wb' csvfile=file(fileName,mode) writer=csv.writer(csvfile) if mode=='wb': writer.writerow([name.encode('gb18030') for name in self.rowName]) writer.writerow([d.encode('gb18030') for d in data]) csvfile.close() def mkdir(self,date): #創建目錄 path = 'landchina/'+datetime.datetime.strftime(date,'%Y')+'/'+datetime.datetime.strftime(date,'%m') isExists=os.path.exists(path) if not isExists: os.makedirs(path) def saveAllInfo(self,allLinks,date): for (i,link) in enumerate(allLinks): linkContent=data=None linkContent=self.getLinkContent(link) data=self.getInfo(linkContent) self.mkdir(date) self.saveInfo(data,date) print 'save info from link',i+1,'/',len(allLinks) 你可以去神箭手云爬蟲開發平臺看看。在云上簡單幾行js就可以實現爬蟲,如果這都懶得做也可以聯系官方進行定制,任何網站都可以爬,總之是個很方便的爬蟲基礎設施平臺。這個結構化如此清晰的數據,要采集這個數據是很容易的。 通過多年的數據處理經驗,可以給你以下幾個建議:1. 多線程2. 防止封IP3. 用Mongdb存儲大型非結構化數據了解更多可以訪問探碼科技大數據介紹頁面:http://www.tanmer.com/bigdata我抓過這個網站的結束合同,還是比較好抓的。抓完生成表格,注意的就是選擇欄的異步地區等內容,需要對他的js下載下來隊形異步請求。提交數據即可。請求的時候在他的主頁有一個id。好像是這么個東西,去年做的,記不清了,我有源碼可以給你分享。用java寫的我是爬蟲小白,請教下,不是說不能爬取asp的頁面嗎?詳細內容頁的地址是”default.aspx?tabid=386&comname=default&wmguid=75c725。。。“,網站是在default.aspx頁讀取數據庫顯示詳細信息,不是說讀不到數據庫里的數據嗎?來源:php中文網